Content-Based Storage in the Cloud
One derivative of the NoSQL movement that rediscovers non-relational storage approaches lately is a content-based value store. Such a store is similar to a Key-Value store but uses a cryptographic hash of the value as key.
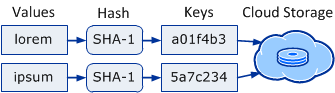
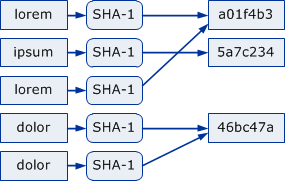
An SHA-1 hash of the value is good enough to identify it
The SHA-1 hash function is unique, meaning that for every value there's exactly one key that can be computed using SHA-1, hence value implies key. We can always compute the unique key of a value.
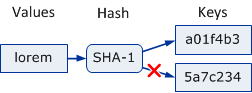
The probability of an SHA-1 hash collision is extremely low. The most cited numbers show that you'd need 1024 values in order to cause a 50% chance of a collision. Even with a whopping 1018 distinct values the likelihood of at least one collision is already down at 10-9. Hence, a key refers to a single value with extremely high probability. While the SHA1 function is not strictly injective, it is approximatively injective enough for almost all practical applications.
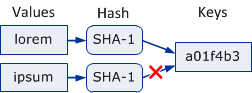
Note that this is different from common non-distributed Hash Tables where a very short hash function is used to directly jump fast to an inner data structure (bucket) containing all items sharing the same hash. The motivation for hashing in such hash tables is to be able to directly compute the position where an item is stored, avoiding long linear or binary searches.
Verifiable Consistency
A nice side effect of using SHA1 is that given the key, the value retrieved from the storage can be verified (detect data corruption or tampering) simply by recomputing its SHA-1 hash and comparing it to the key. You can even digitally sign a key and by that implicitly sign its value and all those referred by it.
Keys are uniformly distributed
When using the common hex string format, the 160bit long keys are always 40 characters long and look something like this:
1:
|
|
We can safely treat them as if their characters were distributed uniformly (0-9, a-f). This brings some advantages especially when used in a distributed or cloud-like scenario, as simple prefix ranges (like 0-3, 4-7, 8-b, c-f) can be used for partitioning and distributed processing.
On the other hand this means that you can't use other indexed keys or ordering out of the box without further logic or storage on top of it.
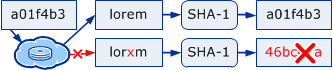
The value of a key is fixed and can't be changed
The value associated with a key can never change. If you store an updated value, you'll get a new key for it and update the reference to this new key. This has severe consequences on where this storage scheme can be used efficiently. For example, a typical relational data model with cyclic relations wouldn't fit at all to such a content-based data store.
However, in practice in a cloud-like application this is often not that much of an issue. Even more so as soon as you realize that the existence of read-only stale yet still consistent data is not an issue either (see CQRS).
Again this fits very well with distributed and cloud computing, as it becomes trivial to aggressively cache values locally. If a value is found in the local cache it is guaranteed to be up to date (since values can't change), so you don't even have to check for timestamps or whether it has been changed remotely. Since in Azure the instances come with a lot of local storage, a simple MRU cache for a few GB can save you a lot of downloads and roundtrips if you use only a relatively small number of instances or have managed to create some weak affinity between jobs and Azure instances.
Example: Large Queue Messages
Azure Queues have content size limitations, that's why Lokad.Cloud implements logic to let messages transparently overflow to blob storage. To do that it needs a way to store a value in a blob that it can retrieve later by some identifier. This identifier is then packed to the actual message. There's no need to access it in any other way, so it's a perfect candidate for a content-based value store.
In my experience, in real life the probability that a message is processed on the same worker that originally put it there is often high or at least not negligible. In all these cases, a cached content-based value store would save you from having to download these blobs completely, but still work correctly otherwise.
Implicit Value-Deduplication
Since the same value leads to the same key, trying to store the same value twice means you get the same storage location and the value gets stored only once. The second trial can even be aborted early by provoking a precondition violation, or skipped completely if it is already in the local cache (depending on the deletion plan).
Example: Daily Backup Snapshots
I recently wrote a small service that periodically takes full snapshots of all tables and blobs of a set of Azure storage accounts to a separate account, keeps the last N snapshots each and removes the rest. Often only a small subset of blobs or table entities actually change in a day. Had I used content-based storage, I could have saved a lot of storage (and thus cost) by deduplication without having to implement complicated incremental or differential backups. Taking a snapshot would likely also have taken less time thanks to some saved uploads.
Trivial Distribution and Replication
Other than any classical relational databases and key value stores, replication and distribution of data in such a content-based value store is trivial since there can't be any conflicts. This is why the caching mentioned above works so well. Replication simply means to copy the values of all missing keys over to the target. A consequence of this is that for some scenarios there's no technical need for a single master database. A peer can synchronize with any other peer, resulting in full peer to peer support. Distributed hash tables (DHT) as used by most file sharing solutions including BitTorrent work similarly and turn out to be very efficient.
History Consistency and Versioning
Since values can't change, they remain consistent with each other even when they become stale. That's why this approach is used by most of the popular distributed version control systems like Git and Mercurial as well.
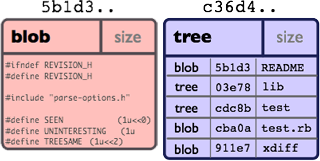
The Git object model is nicely described in the git community book (the following two images are taken from there). In essence, all objects are stored just as described here. In addition to data blobs (i.e. source code files) there are also tree objects representing a folder simply by listing all the SHA-1 keys of its child elements, again stored by its hash:
If a file changes in git in a new revision, it will get a new hash. The folder/tree containing it will update that hash in its list, and in turn will itself get a new hash. Both the old a new version are therefore still available completely and consistently simply by referring to the hash of the respective version of the tree.
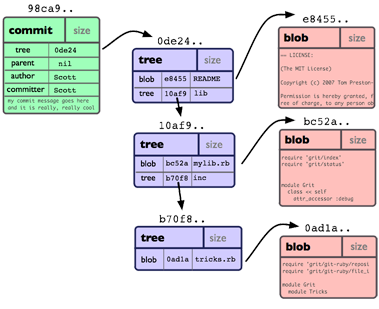
Historical consistency can be useful for all kind of applications. Note that this approach persists snapshots of values and content, not how they are changed. This is thus a dual counterpart to concepts like event sourcing where only the actions causing changes of the values are persisted but not the actual values.
Append-Only Storage or Value Scavenging
Unless you need an append-only storage, you need to be careful about deleting values in such a system. Since there is implicit deduplication, you can't just delete what you've just inserted since the same value could also be used in other places. There are several approaches how you can attack this, depending on your scenario:
Garbage Collection: If there is a hierarchy where all values are referenced by another value, you can follow the tree from time to time and then remove all values you haven't seen. This is used by all the distributed version control systems. Be careful about race conditions though.
Reference Tracking: Use metadata to list all keys or items referring a value. If you remove the last reference, remove it. This can be combined with garbage collection. You can also use reference counters, but they are difficult to handle correctly in an unreliable world like a cloud environment where instantaneous VM shutdowns without prior notice are to be expected.
Time-Based: You "touch" a value (update a timestamp in the metadata) whenever it is used, and from time to time remove all items that haven't been used for a while. Note that that causes a lot of round trips (although they could be performed asynchronously in the background).
Limited Lifetime: Sometimes its good enough to just define that a value can safely be removed after a day or a month.