Lokad.Cloud Architecture Refresh
In a recent post about new deployment and versioning approaches in Lokad.Cloud I mentioned that I'm also heavily refactoring the old cloud service framework and runtime. That refactoring was long due but also required to support these new approaches effectively.
In essence, developing Cloud Services still works as before. There is a framework library (Lokad.Cloud.Services.Framework) that provides base classes for a small set of service types that you can derive from. The following figure shows the dependencies of all involved components:
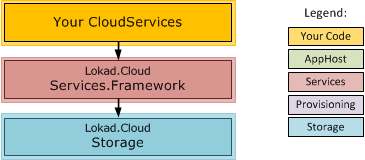
Previously the framework also contained the complete runtime with AppDomain isolation and all. This is no longer the case (since we want to use the new deployment approach). Instead, the framework now comes with service runners, which are lightweight classes that take already created service instances plus their settings and can be used to run cloud services directly in the current thread, without any isolation. This comes handy for easier debugging and testing. In simple scenarios it might even be good enough for production or integration into another system.
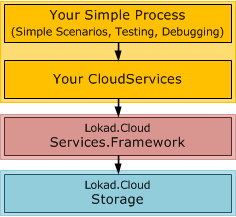
However, in production scenarios you often do want proper isolation, more robustness and some deployment story. That's where the new AppHost comes in.
Introducing the Lokad.Cloud AppHost
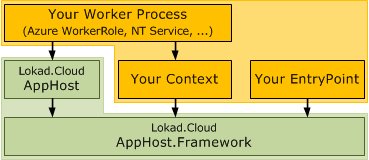
The new deployment approach is currently implemented in a prototype, Lokad.Cloud AppHost. I'll introduce the AppHost in more details in a later post. Important for now is that it comes with two assemblies, AppHost and AppHost.Framework. AppHost.Framework is essentially a set of contracts, while AppHost implements the actual runtime environment. Both are quite small and simple. The typical architecture anticipated in the prototype is as follows:
-
Your Context
Represents the whole environment where the AppHost is executed to the AppHost itself. This is why AppHost has no dependencies at all (except SharpZipLib, but that will likely be dropped soon). Thanks to this abstraction, AppHost is completely neutral to where and how it is executed. The context also provides a deployment reader and thus decides where and how application deployments are stored. -
Your Worker Process
This would be the process where the whole application is executing, e.g. a Windows Azure WorkerRole, an Windows Service or even some CLI application. The worker builds the "host context", creates an AppHost Host instances using said context and then starts and stops the host on demand. -
Your Entry Point
The entry point of your application that is hosted using the AppHost. The entry point class type is chosen in the deployment itself, and automatically created in one or more runtime cells (again as specified in the deployment), isolated by AppDomain and in its own thread.
Note that this figure does not mention Lokad.Cloud Services, Storage or Provisioning at all. Indeed, AppHost could be used to host all kind of applications (e.g. even some business application based on Lokad.CQRS).
Hosting Lokad.Cloud Services in AppHost
That's all nice and well, but the primary scenario is to run Lokad.Cloud Services. One of the design targets of Cloud Services have always been simple usage, achieved in parts by tight integration of our storage and provisioning toolkits into the services framework (opinionated on infrastructure). Luckily this gives us the opportunity to fully provide complete AppHost Context and EntryPoint implementations. The complete services solution now looks like this:
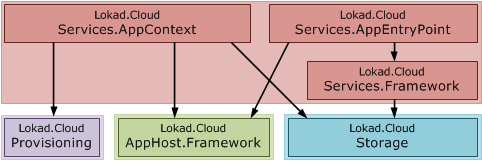
Note that the services framework no longer depends on Provisioning, and does not depend on any AppHost infrastructure at all. Neither AppHost nor Provisioning thus leak into your cloud services implementations. The separation between AppContext and AppEntryPoint also reflects that they run in different places: AppContext is used directly in the host process, while AppEntryPoints run in the isolated runtime cell AppDomains. This becomes clear when we visualize the complete solution:
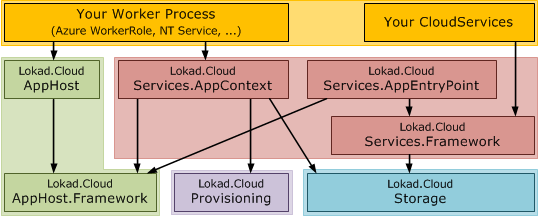
This looks quite complicated and like a lot of infrastructure just to support that little yellow box on the top right. But this is somewhat misleading, as all the components are very focused and most of them small and independent.
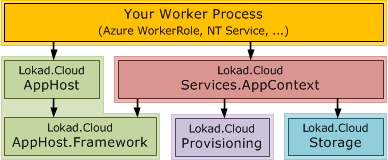
A closer look at what is actually deployed on the worker (e.g. your Azure WorkerRole) reveals that there is really nothing more than the AppContext opinionating the AppHost towards Lokad.Cloud Provisioning and Storage and then connecting this context with the AppHost and run it in the worker process:
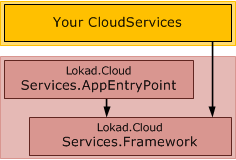
Similarly, the actual (versioned) application deployments need to contain only the assemblies shown in the following figure. Obviously there are your cloud services, but also the entry point and the service framework:
All these parts are thus movable and "replaceable" per deployment. This brings up some nice opportunities, as you can patch and replace any of these assemblies in specific deployments without worrying about compatibility with the worker process (this used to be an issue in the past). You can change the scheduling, add new cloud service types or even replace the framework and entry point completely with your own code. Technically there's also no need to keep it separated into three assemblies, but the isolated EntryPoint helps keeping some dependencies like AppHost out of your cloud services.
Overengineered?
I claim it is not. If you do want all of these:
-
Storage:
Robust storage (especially important for remote cloud storage) that is very easy to use -
Provisioning:
Automatically scale your worker instances (cloud scenario) based on demand -
Deployments:
Easily switch between deployments, fast, versioned including settings, in Git style. -
Runtime:
Robust multi-cell cloud application hosting, self-healing to some degree. -
Cloud Services:
Compute agents that are easy to implement.
then you do need all these components. You can either have them all in one huge monolithical assembly and your logic depending on all of them, or you can isolate them logically, keep them simple and focused and avoid unnecessary dependencies, as suggested in the presented architecture.