Lokad.Cloud Application Deployment and Versioning Refresh
At the very beginning of the Lokad.Cloud project we decided to not rely on the Windows Azure management tools to deploy new versions of our application. Instead we implemented a dynamic worker role - initially deployed once using the Windows Azure tools - that provides a runtime environment that can load and unload applications on demand, without even recycling the azure virtual machine. The applications are isolated in a separate AppDomain so we can unload them safely, plus for sandboxing.
Disclaimer: I'm a major contributor to the Lokad.Cloud opensource project. Lokad.Cloud is a framework for distributed computing in Windows Azure, plus a set of independent toolkits like Lokad.Cloud.Storage for simpler and more reliable cloud storage access and Lokad.Cloud.Provisioning for dynamic worker auto-scaling. We use Lokad.Cloud at Lokad to deal with our massive and rapidly changing computation demands.
This approach worked out nicely for us, both for apps that don't change for months and apps where we often have multiple redeployments per hour. Yet over the last year we gained a lot of experience and discovered some dark spots in the current stable release. Most of them were "good enough" back then, but are starting to get in the way:
-
Non-atomic deployments
The deployment mainly consisted of an assembly blob (zip file containing all the assemblies), a config blob (IoC configuration to add application-specific registrations and config like additional connection strings) plus service settings distributed over multiple blobs. Since workers automatically discover new deployments themselves, deployments are not atomic. Some worker could see new assemblies but old and possibly incompatible IoC configuration, causing undefined behavior until it catches up. -
Lots of blobs to poll for changes
By design, all workers are completely self-contained and self-healing. A worker is never "contacted" in any way from outside, except via cloud storage (queues, blobs, tables). Since the deployments are non-atomic and in particular service settings spread over multiple blobs, they all have to be polled for change repeatedly on every worker. Polling for changed etags is not expensive but causes latency and can sum up if there are lots of services and worker instances. Even worse, some service settings also contained state (for simplicity) and thus change quite often. -
Replacing an application is easy, getting back not so
It is very easy to redeploy, but there's no way to get back to the previous state unless you have a backup ready or can rebuild it from sources. Upgrading becomes much safer if it is easy to get back, reducing the burden of shorter deployment cycles. -
Growing demand for stronger runtime
E.g. to support multiple runtime "cores" or "cells" on each worker with independent scheduling and customizable assignment/affinity.
Hence I started refactoring the Lokad.Cloud service framework recently, including reworking the handling of app deployments (not released yet):
Concentrating service settings to single blob
Cloud services have been refactored so that they no longer have to manage their own settings. Instead all settings are now stored in a single blob. Settings include parameters like whether a service is disabled or the trigger interval for scheduled services. Settings generally change rarely (e.g. manually through the management console) so the new settings blob still changes only rarely and conflicts are no issue (can be handled with optimistic concurrency). This brings the number of blobs to poll for drastically down to three, reducing a lot of unnecessary storage I/O and thus latency.
Separating deployments from currently active deployment
Previously there were just three blobs (assemblies, config and settings) for the currently active deployment. Changes were almost immediately applied on all workers.
From now on we can have multiple deployments exist in parallel. The "currently active deployment" is given by a pointer to the chosen deployment. Deployments are now read-only. If we want to change anything in a deployment (e.g. change some settings) we essentially create a new deployment and update the active deployment pointer to point to that new deployment instead. Let's call that new pointer HEAD.
Only one blob to poll
Since deployments are read-only, the only blob we have to poll is HEAD. Since no other polling is needed, we can easily poll more often to get much more reactive workers. If we poll once every 15 seconds, we get transaction costs of around US\(0.17 per month per active worker plus maybe US\) 0.10 for bandwidth (note that most of the time the HTTP packets will only have headers, no body payload). This is negligible compared to the worker instance cost.
Content-based storage for deployments
I've introduced content-based storage in a previous blog post. The general idea is to identify data by its hash (often SHA-1 or SHA256) resulting in automatic deduplication and verifiable referential consistency. It is an ideal concept for versioning, that's why it is also broadly used in the popular git distributed version control system. It is also an ideal approach for managing our deployments. Like this:
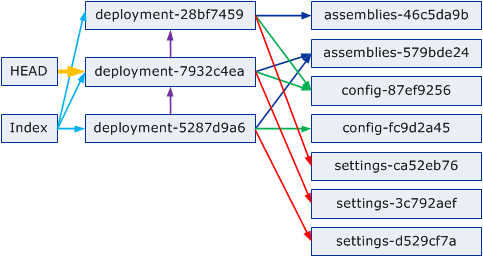
Think of assemblies, config and settings as files, deployments as commits (pointing to one assemblies, config and settings blob each, shared if equal), and HEAD as head just like in git. All the arrows include the full hash of the target (as part of their name, shortened in the diagram).
The Index is just a redundant list of all deployments for easier management so we don't have to iterate through all available deployments all the time. In a similar way a History blob could be interesting to track the last few deployments and when they have been deployed. Note that HEAD and Index (and History) are the only mutable blobs, all the others are readonly, although they can be garbage collected.
The arrows between deployments will likely be dropped, they don't seem provide any value in practice.
Prepare deployment, then activate atomically
Both the creation of a deployment (based on assemblies, config and settings) and actually activating it (by changing HEAD to point to it) are now atomic operations. They still can happen at different times though, so you can prepare one or more deployments but activate them much later, if at all. The applications can be completely unrelated, so you can use this mechanism to quickly switch between different applications.
Note that it still takes a while until all workers have detected the change, so there will be a phase where different workers (on different VMs and servers) may have different applications running. There are ways to deal with this if it is an issue, see below.
Get back to the previous version
... is as trivial as looking up the previous version in the History or Index and change HEAD to point to it.
Changing service settings
If you change some settings in the web console, for example disable a service or change a trigger interval, a new settings blob will be created, then a new deployment referring to the new settings, and in the end HEAD will be changed to point to the new deployment. If you decide to change it back, the new settings will already exist (with the same hash), so in effect only the HEAD blob will be changed back to point to the previous deployment (plus the History updated if available). Note that you won't see much of that in practice as the management classes will handle it automatically.
Handling changes in the runtime
If the runtime detects a changed HEAD it will immediately load the deployment blob. Since it knows its current deployment and since the blobs are named after their content hash and readonly, it can simply compare the names to detect what blob has been changed. If either assemblies or config has changed, the runtime will have to restart all the processes, but if only the settings changed then it's usually enough to just adapt the scheduling appropriately. Settings changes therefore still have a rather small impact in practice, despite switching to a completely different deployment in the storage.
Forcing a deployment form an application
Sometimes you need to ensure that a message is processed by a specific deployment. For example, we sometimes deploy a new version and then want to do some computation on exactly that version. To achieve that we could either wait, or include the deployment hash in the message and make the application force the runtime to load exactly that deployment if it isn't matching already. For that and similar purposes I suggest to provide some way for services to send commands to the local runtime, like commands to enforce loading of the head or some specific deployment as soon as possible.
Multi-Head Scenario
This is unrelated to deployments, but the new runtime will also support multiple processes ("cells") in parallel, isolated in separate AppDomains and threads and with independent scheduling. Services settings contain a new cell affinity parameter to control in what cells a service should be executed. This can be useful e.g. to create a cell for low latency queue services or to avoid blocking when some services can have long processing times but there are only few worker instances available.
Now technically it would be possible to load different applications or versions in different cells at the same time, with separate HEADs for each cell. This would bring the service interleaving approach to a new level. Not sure how useful it would be in practice though (plus it would require some work to decide which app can choose the number of worker instances), so I won't follow that idea any further for now.
Too complicated?
This all seems very complicated just to do deployments. How could we simplify it but still satisfy our requirements?
-
Single blob only:
Store everything (assemblies, config, settings) in a single blob and give the currently active blob a special name (like "current" or still "HEAD"). Way simpler. Disadvantage: the whole blob can get large and has to be touched by every single settings change. Unlikely an issue in most deployments though. -
Drop the hashing:
SHA is built in, so this is not really a big simplification. Disadvantage: we'd loose deduplication -
Toggle instead of versioning:
Just provide two versions of each blob, which can be switched on demand (similar to Azure staging vs. production deployments). The staging blobs would be edited and when done switched somehow in an atomic way (e.g. HEAD blob pointing to version again). This may simplify management remarkably. -
Outsource the versioning:
Use a proofed version control system instead, like git. Technically even subversion would work (I've tested subversion on Azure in the past, worked fine. For git we could even use one of the native git libraries). Disadvantage: checking a remote repository for changes is more expensive than a simple azure blob storage ETag check (git beats svn here). In the worst case we could work around that by introducing a HEAD blob in azure storage again, containing the current head revision/hash. We would then update that blob after every commit and poll it from the workers at much higher frequency. Advantage: Much more robust versioning, we could drop the zip files (simply version the assemblies directly), and we'd get push deployment for free.
Personally I like that last alternative using git the most.
Feedback
What do you think? Too complicated? Overengineered? Schould I use a real git repository instead? Let me know. Thanks!
(Migrated Comments)
Rinat Abdullin, July 23, 2011
Once again, that's a fine post, just like the previous one on hashing. I loved rereading it.
Just a few thoughts.
- How hard would be to use Lokad.Cloud cell management with AppDomains without using actual services and message dispatch?
- I think that given versioning sandbox/production toggle is just an overkill (it duplicates the logic). swaps are just a way to shift focus from one version to another, while keeping the ability to roll-back.
- Hashing and separated blobs, as I believe, are a must for a simple implementation. They allow to keep stuff simple and decoupled. Besides, the complexity could be reduced by the tooling.
- Git (versus self-implemented versioning) is just a way to deliver changes in my opinion (besides, versioned settings). So it should not be that different for blob or git storage (we just poll for changes and pull the version specified by head). I'm wondering how well would private github repo work here...
In case of blob, head is stored in blob storage (human-editable JSON), pointing to the deployment blobs In case of full git, head is in git In mixed scenario, head is stored in blob storage, pointing to the git version/url
Sorry for pushing that much of my rambling here :)